
Data Validation Framework in Apache Spark for Big Data Migration Workloads
In Big Data, testing and assuring quality is the key area.
However, data quality problems may destroy the success of many Data Lake, Big Data, and ETL projects. Whether it’s a big data or small, the need for the quality data doesn’t change. Moreover, high-quality data is the perfect driver to get insights from it. The data quality is measured based on the business satisfaction by deriving the necessary insights.
Steps included in the Big Data validation.
- Row and Column count
- Checking Column names
- Checking Subset Data without Hashing
- Statistics Comparison- Min, Max, Mean, Median, 25th, 50th, 75th percentile
- SHA256 Hash Validation on entire data
To learn complete tutorials visit:big data and hadoop training
Debugging
When there is a mismatch between source and sink, then we should know how to find out particular corrupt data within the entire data which may include 3000+ columns and Millions of records.
Let’s discuss the same by looking into the columns that come in the way.
Context
Under Big Data, we have transferred the data from MySQL to Data Lake. Moreover, the quality of the data has to be verified before it is ingested by downstream applications.
For example purpose, I have gone with a sample customer data (having 1000 records) within Spark Dataframe. However, the demo is with a small amount of data, this solution can be scaled to the enormous data volume.
Plot-1
Thus, the same data exists within two Dataframes, so our Data validation framework will be a green signal.
I have intentionally changed the data in the previous records in the 2nd data frame. So, we can see how this hash validation framework helps.
Let’s see the steps in the data validation process as this is the core part of this validation in Big Data.
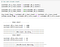
Step-01: Row and Column count
This check will happen in a typical data migration pipeline.

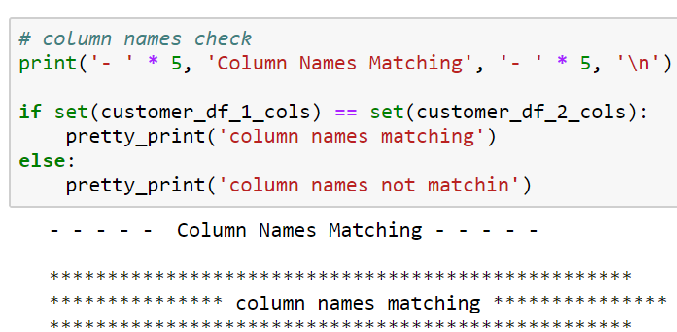
Step-02: Checking Column Names
The following check will make sure that we don’t have corrupt or additional columns in this Big Data validation.

Step-03: Checking Subset Data without Hashing
This type of checking is like fruit to fruit comparison. Moreover, it means that this will validate the actual data (Big Data) without applying the hash function. But, this checking has a limitation up to a few records only, as this may consume more resources if we do it using Big data or huge data.
Step-04: Statistics Comparison using — (Min, Max, Mean, Median, 25th, 50th, 75th percentile)
In rare cases, there can be a collision or attack in hash validation. This may lead to data corruption. Moreover, this can be evaded by calculating statistics on each column in the data.
Step-05: SHA256 Hash Validation on entire data
For this example, I have chosen SHA256 but there are some other hashing algorithms also available as well such as MD5.
Hash Function
Hashing algorithms or functions are useful to generate a fixed-length result (the hash, or hash value) from the given input. Moreover, this hash value is an abstract of the actual data.
EX:
- Hash function
Good boy
- Hash Value
2debae171bc5220f601ce6fea18f9672a5b8ad927e685ef902504736f9a8fffa
The above example explains the function hash and its related hash value under the SHA256 algorithm. A small change in the character can change the total hash value.
This kind of technique is extremely used in digital signatures, authentication, indexing Big Data in hash tables, detecting duplicates, etc. Moreover, this technique is useful to detect whether a sent file didn’t suffer any accidental or intentional data corruption.
Verifying a Hash
In Big Data, data can be compared to a hash value to ascertain its integrity. Typically, data is hashed at a precise time and the corresponding hash value is secured in some way. At a later time, the data can be divided again and compared to the secured value. In case, the hash value matches, the data has not been modified. If the value does not match, it means the data has been corrupted or faulted. For this system to work, the secured hash or division must be encrypted or kept secret from all suspicious parties.
Hash Collision
A collision or attack occurs when two different keys include the same hashCode. This may happen as two unlike objects within Java can have a similar hashCode. Moreover, a Hash Collision is an attempt to determine two input strings of a function hash that gives the same hash result. Because these functions have immense input length and a predefined output length. Thus, there is automatically going to be the possibility of two distinct inputs that give the same output hash as a result.
When we have millions of records and 3000+ columns, it becomes hard to compare the source and destiny system for data mismatch in Big Data. For doing this, we need a big memory and calculation power engines. To address this, we are using Hashing to link all the 30k+ columns together in a chain into one single hash value column. This just includes 64 characters in length. This amount is unimportant while comparing the 30k+ column length and size.
Why Data migration is important in Big Data?
Nonetheless of the actual purpose of data migration in Big Data, the goal is generally to enhance performance and competitiveness.
Anyhow, we have to get it right!
When the migration is less successful, it results in incorrect data that includes dismissals and unknowns. This may happen even when the source data is completely usable and appropriate. Furthermore, any issues that do exist in the source data can be turned up while bringing it into a new, more advanced system.
A complete Big Data migration strategy averts a sub-parallel experience that ends up developing more issues than it resolves. Apart from missing deadlines and exceptional budgets, incomplete plans can cause migration projects to fail completely. In planning and strategizing the work, teams need to give complete attention towards migrations, instead of making them secondary to another project with a big scope.
A strategic data migration plan should include the reflection of the following important factors:
Knowing the data —
Before performing the migration, all source data needs a complete audit check. Unexpected issues may occur in case this step is ignored.
Cleanup:
Once the user recognizes any problem with the source data, they must be resolved in less time. Moreover, this work may require additional software tools and third-party resources due to the large scale work.
Data Validation Framework in Apache Spark for Big Data Migration Workloads
In Big Data, testing and assuring quality is the key area.
However, data quality problems may destroy the success of many Data Lake, Big Data, and ETL projects. Whether it’s a big data or small, the need for the quality data doesn’t change. Moreover, high-quality data is the perfect driver to get insights from it. The data quality is measured based on the business satisfaction by deriving the necessary insights.
Steps included in the Big Data validation.
- Row and Column count
- Checking Column names
- Checking Subset Data without Hashing
- Statistics Comparison- Min, Max, Mean, Median, 25th, 50th, 75th percentile
- SHA256 Hash Validation on entire data
Debugging
When there is a mismatch between source and sink, then we should know how to find out particular corrupt data within the entire data which may include 3000+ columns and Millions of records.
Let’s discuss the same by looking into the columns that come in the way.
Context
Under Big Data, we have transferred the data from MySQL to Data Lake. Moreover, the quality of the data has to be verified before it is ingested by downstream applications.
For example purpose, I have gone with a sample customer data (having 1000 records) within Spark Dataframe. However, the demo is with a small amount of data, this solution can be scaled to the enormous data volume.
Plot-1
Thus, the same data exists within two Dataframes, so our Data validation framework will be a green signal.
I have intentionally changed the data in the previous records in the 2nd data frame. So, we can see how this hash validation framework helps.
Let’s see the steps in the data validation process as this is the core part of this validation in Big Data.
Step-01: Row and Column count
This check will happen in a typical data migration pipeline.
Step-02: Checking Column Names
The following check will make sure that we don’t have corrupt or additional columns in this Big Data validation.
Step-03: Checking Subset Data without Hashing
This type of checking is like fruit to fruit comparison. Moreover, it means that this will validate the actual data (Big Data) without applying the hash function. But, this checking has a limitation up to a few records only, as this may consume more resources if we do it using Big data or huge data.
Step-04: Statistics Comparison using — (Min, Max, Mean, Median, 25th, 50th, 75th percentile)
In rare cases, there can be a collision or attack in hash validation. This may lead to data corruption. Moreover, this can be evaded by calculating statistics on each column in the data.
Step-05: SHA256 Hash Validation on entire data
For this example, I have chosen SHA256 but there are some other hashing algorithms also available as well such as MD5.
Hash Function
Hashing algorithms or functions are useful to generate a fixed-length result (the hash, or hash value) from the given input. Moreover, this hash value is an abstract of the actual data.
EX:
- Hash function
Good boy
- Hash Value
2debae171bc5220f601ce6fea18f9672a5b8ad927e685ef902504736f9a8fffa
The above example explains the function hash and its related hash value under the SHA256 algorithm. A small change in the character can change the total hash value.
This kind of technique is extremely used in digital signatures, authentication, indexing Big Data in hash tables, detecting duplicates, etc. Moreover, this technique is useful to detect whether a sent file didn’t suffer any accidental or intentional data corruption.
Verifying a Hash
In Big Data, data can be compared to a hash value to ascertain its integrity. Typically, data is hashed at a precise time and the corresponding hash value is secured in some way. At a later time, the data can be divided again and compared to the secured value. In case, the hash value matches, the data has not been modified. If the value does not match, it means the data has been corrupted or faulted. For this system to work, the secured hash or division must be encrypted or kept secret from all suspicious parties.
Hash Collision
A collision or attack occurs when two different keys include the same hashCode. This may happen as two unlike objects within Java can have a similar hashCode. Moreover, a Hash Collision is an attempt to determine two input strings of a function hash that gives the same hash result. Because these functions have immense input length and a predefined output length. Thus, there is automatically going to be the possibility of two distinct inputs that give the same output hash as a result.
When we have millions of records and 3000+ columns, it becomes hard to compare the source and destiny system for data mismatch in Big Data. For doing this, we need a big memory and calculation power engines. To address this, we are using Hashing to link all the 30k+ columns together in a chain into one single hash value column. This just includes 64 characters in length. This amount is unimportant while comparing the 30k+ column length and size.
Why Data migration is important in Big Data?
Nonetheless of the actual purpose of data migration in Big Data, the goal is generally to enhance performance and competitiveness.
Anyhow, we have to get it right!
When the migration is less successful, it results in incorrect data that includes dismissals and unknowns. This may happen even when the source data is completely usable and appropriate. Furthermore, any issues that do exist in the source data can be turned up while bringing it into a new, more advanced system.
A complete Big Data migration strategy averts a sub-parallel experience that ends up developing more issues than it resolves. Apart from missing deadlines and exceptional budgets, incomplete plans can cause migration projects to fail completely. In planning and strategizing the work, teams need to give complete attention towards migrations, instead of making them secondary to another project with a big scope.
A strategic data migration plan should include the reflection of the following important factors:
Knowing the data —
Before performing the migration, all source data needs a complete audit check. Unexpected issues may occur in case this step is ignored.
Cleanup:
Once the user recognizes any problem with the source data, they must be resolved in less time. Moreover, this work may require additional software tools and third-party resources due to the large scale work.
Maintenance and security:
Data undergoes humiliation after some time, making it untrustworthy. This means there must be the maintenance of data quality by placing controls.
Governance:
It becomes necessary to track and report on data quality because it allows a better understanding of data honesty. Furthermore, the processes and tools used to generate this information should be highly useful and do automated functions where possible.
Final Thought
Thus, we have discussed how a framework in Spark for Big Data migration validates data. However, poor data quality will put a burden on the working team’s quality time in fixing them. I hope, this article will help to address the data quality problems after migration from source to destination using Spark. Get more insights from big data and hadoop Data undergoes humiliation after some time, making it untrustworthy. This means there must be the maintenance of data quality by placing controls.
Governance:
It becomes necessary to track and report on data quality because it allows a better understanding of data honesty. Furthermore, the processes and tools used to generate this information should be highly useful and do automated functions where possible.
Final Thought
Thus, we have discussed how a framework in Spark for Big Data migration validates data. However, poor data quality will put a burden on the working team’s quality time in fixing them. I hope, this article will help to address the data quality problems after migration from source to destination using Spark. Get more insights from big data and hadoop online training



No comments: