
Hadoop MapReduce partition in Hadoop administration
MapReduce is the heart of Hadoop programming environment. Hadoop MapReduce ensures massive scalability in the Hadoop cluster, which consists of many servers. People who are familiar with the clustered scale-out data processing framework will consider MapReduce concepts easier to understand in Hadoop. It might not be as easy for new entrants to the platform but Hadoop MapReduce features will help them understand what it is and how it works. Before learning about MapReduce partition let us discuss about Hadoop MapReduce and its features briefly.
To more information visit,ITGuru's hadoop admin training Blog
Hadoop MapReduce
MapReduce is simply a variation of the Hadoop programming environment performing two distinct tasks. Map job takes specific data sets and transforms them to various data sets. Individual elements in the sets are broken into key or value pairs or tuples. Reduce job is to obtain the output generated by Map as input and then combine it into smaller sets of tuples. Reducing work would always follow the job on the Map.
Features of Hadoop MapReduce
Hadoop MapReduce architecture function can be understood by simply taking the example of files and columns. For example; the user can have multiple files with two columns; one representing the key s and another representing the value in the Hadoop cluster. Real life tasks may not be as easy but this is how the MapReduce Hadoop works.
Tasks of Hadoop Mapreduce
MapReduce tasks in real time can contain millions of rows and columns, and may not have been well formatted either. But MapReduce's fundamentals of working would always remain the same. City as the key and rainfall quantum could be an example, as the value that provides the key / value pair needed for MapReduce to function.
Hadoop MapReduce Data
Data collected and stored, using the MapReduce function, will help find out the maximum and minimum rainfall per area. If there are ten files then they'd be split into ten Map tasks. - mapper will operate on one of the files, evaluate the data, and return in each of the cases the maximum rainfall or minimum rainfall required.
Performance of Hadoop MapReduce
Performance streamed out of all the ten files will be fed into the Reduce process afterwards. The Reduce function would combine all the results of the inputs and the output generating a single value for each city. Thus a common final result sheet showing the rainfall in each of the cities would be generated.
The process is straight forward. It's like tasks that were performed when computers and information technology hadn't evolved that far and everything was done by hand. People were sent to various places to collect the data, and they would return to their head office and submit the data collected. In MapReduce this is exactly how the Map works. The Hadoop MapReduce function comes with both combiner and partitioner in Hadoop. In this article let us discuss mapreduce partition.
Hadoop Mapreduce Partitioner
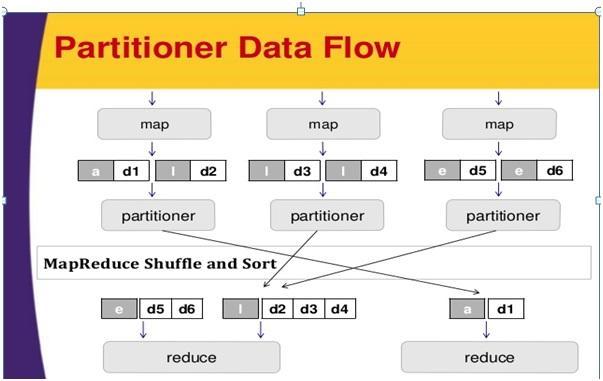
A partitioner in the processing of an input data set acts like a state. The process of partitioning occurs after the Map phase and before the Reduce phase.
The number of partitioners is equal to that of reducer numbers. That means that a partitioner will divide the data by the number of reductors. Therefore, one Reducer processes the data passed from a single partitioner.
Partitioner
A partitioner partitions intermediate Map-output key-value pairs. It uses a user-defined condition to partition the data works like a hash function. Then the total number of partitions is the same as the number of tasks for the job which are reduced. Let's take an example to understand the workings of the partitioner.
Implementing Hadoop MapReduce Partitioner
Let's assume we have a small table called Employee with the following data, for convenience. You can use this sample data to show how the partitioner functions as our input data collection.
Tasks to Hadoop MapReduce partitioner
The map task accepts the key-value pairs as input, while in a text file we have the text info. The data for this map function is as follows.
Input
The pattern such as some special key + filename + line number" (e.g. key = @input1), and the value will be the data in that line (e.g.: value = 1201\t gopal \t 45\t Male \t 50000).
System
This map function is conducted as follows .
Read the value (record data), which comes from the list of arguments in a string as the input value.
Separate the gender by using the split function and store it in a string variable
String] [str = .toString().split("\t), "-3);
Gender = string[3];
Send the gender information and the record data value from the map task to the partition task as output key-value pair.
Context.write(new word(general), new text(value))
For all records in the text file repeat all the above steps.
Output
As key-value pairs, you'll get the gender data and the record data value.
Task Partitioner in Hadoop MapReduce
The partitioner task accepts the key-value pairs as their input from the map task. Partition means the data is divided into segments. Based on the age criteria, the input key-value paired data can be divided into three parts, based on the given conditional partition criteria.
Input
All of the data in a key-value pair collection.
Key = Field value for gender in the record.
Value = Whole data value recorded by that gender.
Method
The logic of the partition process runs like this.
Read the value of the input key-value pair for the age field.
String()str = valor.toString().split("\t);
Age of int = Integer.parseInt(str[2]);
With the following conditions test the age value.
- Age under or equal to 20
- Age Less than, or equal to, 30 years.
if(age<=20)
{
return 0;
}
else if(age>20 && age<=30)
{
return 1 % numReduceTasks;
}
else
{
return 2 % numReduceTasks;
}
Output
The entire key-value pair data is segmented into three key-value pair collections. The Reducer functions on each collection individually.
Reducing Tasks Through Hadoop MapReduce Partitioner
The number of partitioner responsibilities is equal to the number of reducer tasks. We have three partitioner tasks here and thus we have to perform three Reducer tasks.
Input
The Reducer executes key-value pairs three times with different collection.
- Key = Field value of the gender in the record.
- Value = That gender 's entire record data.
- Method − For every set the following logic is applied.
- Read the value of each record in the field Salary.
String [] str = val.toString().split("\t", -3);
Note: str[4] have the salary field value.
Check the max variable for salary. If str[4] is the maximum salary, allocate str[4] to max, otherwise skip the step.
if(Integer.parseInt(str[4])>max)
{
max=Integer.parseInt(str[4]);
}
Repeat steps 1 and 2 for each key collection (the key collections are masculine & feminine). You'll find one max salary from the Male key collection and one max salary from the Female key collection after executing these three steps.
context.write(new Text(key), new IntWritable(max));
Output
Finally, in three sets of different age groups you will obtain a set of key-value pair results.
It includes the Male collection maximum salary and the Female collection maximum salary in each age group , respectively.The three sets of key-value pair data are stored in three separate files as the output after running the Map, the Partitioner, and the tasks Reduce.
All three tasks are treated as jobs for MapReduce. These job criteria and specifications should be specified in the Configurations .
- Name of Job
- Key and value input and output formats
- Individual classes for tasks related to map, reduction and partitioner
Configuration conf = getConf();
//Create Job
Job job = new Job(conf, "topsal");
job.setJarByClass(PartitionerExample.class);
// File Input and Output paths
FileInputFormat.setInputPaths(job, new Path(arg[0]));
FileOutputFormat.setOutputPath(job,new Path(arg[1]));
//Set Mapper class and Output format for key-value pair.
job.setMapperClass(MapClass.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//set partitioner statement
job.setPartitionerClass(CaderPartitioner.class);
//Set Reducer class and Input/Output format for key-value pair.
job.setReducerClass(ReduceClass.class);
//Number of Reducer tasks.
job.setNumReduceTasks(3);
//Input and Output format for data
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
Conclusion:
I hope you reach a conclusion about Hadoop MapReduce in this article. You can learn about more functions of Hadoop through hadoop admin online training



No comments: