
Hadoop Ecosystem : Learn the Fundamental Tools and Frameworks
Hadoop is a platform that, using parallel and distributed processing, manages big data storage. Hadoop consists of different methods and mechanisms, such as storing, sorting, and analyzing, dedicated to various parts of data management. Hadoop itself and numerous other associated Big Data instruments are protected by the Hadoop ecosystem.
We will talk about the Hadoop ecosystem and its different fundamental resources in this article. We see a diagram below of the whole Hadoop ecosystem,More info go through big data hadoop course Blog
Hadoop
Let’s start with the Distributed File System ( HDFS) for Hadoop.
HDFS
All data was stored in a single central database under the conventional approach. A single database was not enough to manage the job, with the rise of big data. The solution was to use a distributed strategy to store a large volume of data. Data was distributed to several different databases and split up. HDFS is a specially built file system for storing enormous datasets on commodity hardware, storing data on various machines in different formats.
HDFS comprises two components.
- Name Node-The master daemon is Name Node. Just one active Name Node exists. The Data Nodes are maintained and all metadata stored.
- Data Node-The slave daemon is a data Node. Multiple Data Nodes may exist. The actual data is processed.
So, we spoke about HDFS storing data in a distributed way, but did you know that there are some requirements for the storage system? HDFS splits the data into several blocks, with a limit of 128 MB by default. Depending on the processing speed and the data distribution, the default block size may be modified.
We have 300 MB of data, as seen from the above image. This is broken down to 128 MB, 128 MB, and 44 MB, respectively. The final block handles the remaining storage space necessary, so it doesn’t have to be 128 MB in size. In HDFS, this is how data is processed in a distributed way.
It is also important for you to understand what it sits on and how the HDFS cluster is handled now that you have an overview of HDFS. YARN is doing it, and this is what we’re looking at next.
YARN (Yet Another Negotiator of Resources)
YARN is an acronym for Yet Another Negotiator for Capital. It manages the node cluster and serves as the resource management unit of Hadoop. RAM, memory, and other resources are allocated by YARN to various applications.
There are two components to YARN.
- Resource Manager (Master)-The master daemon is here. It handles resource allocation such as CPU, memory, and bandwidth of the network.
- Node Manager (Slave)-This is the slave daemon and reports to the Resource Manager about the use of the resource.
Let us move on to MapReduce, the processing unit of Hadoop.
Map Reduce
The processing of Hadoop data is based on MapReduce, which processes large quantities of data in a simultaneously distributed way. We can understand how MapReduce functions with the aid of the figure below.
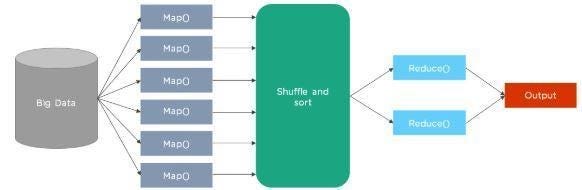
As we see, to finally achieve a production, we have our big data that needs to be processed. So the input data is broken up at the beginning to form the input splits. The first stage is the Map step, where data is passed to generate output values in each split. The mapping step’s output is taken and grouped into blocks of related data in the shuffle and sort process. The output values from the shuffling stage are eventually aggregated. It then returns a single value of the output.
To sum up, the three components of Hadoop are HDFS, MapReduce, and YARN. Let us now, begin with Sqoop, dive deep into the data collection and ingestion tools.
Sqoop
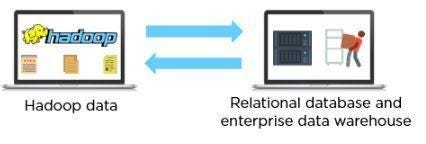
Sqoop is used to move data, such as relational databases and business data warehouses, between Hadoop and external datastores. It imports data into HDFS, Hive, and HBase from external data stores.
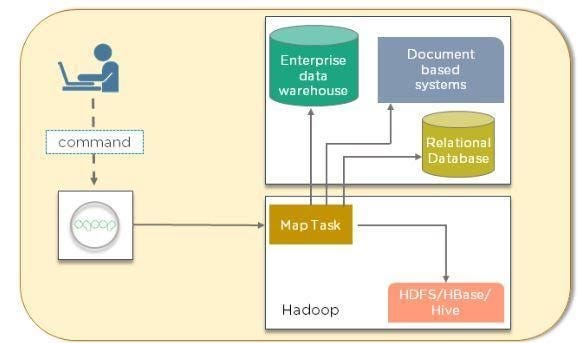
The client machine gathers code, as shown below, which will then be sent to Sqoop. The Sqoop then goes to the Task Manager, which, in turn, connects to the warehouse of enterprise data, systems based on documents, and RDBMS. It can map these assignments into Hadoop.
Flume
Flume is another method for data collection and ingestion, a distributed service for vast volumes of log data collection, aggregation, and movement. It ingests social media, log files, web server data into HDFS online streaming.
As you can see below, information, depending on the needs of your organization, is taken from different sources. The source, channel, and sink are then passed through it. The sink function ensures that the specifications are in line with everything. Finally, it dumps the data into HDFS.
Now let’s take a look at the scripting languages and query languages of Hadoop.
Pig
Yahoo researchers created Apache Pig, aimed primarily at non-programmers. It was designed to analyze and process data sets without the use of complicated Java codes. This offers a high-level language for data processing that can conduct multiple tasks without being bogged down by too many technical terms.
It is comprised of:
- Pig Latin-This is the scripting language for
- Pig Latin Compiler-Translates the code from Pig Latin to executable code
Extract, Pass, and Load (ETL) and a forum for building data flow are also supported by Pig. Did you know that ten Pig Latin script lines are equivalent to around 200 MapReduce work lines? To analyze datasets, Pig utilizes quick, time-efficient steps. Let’s take a closer look at the architecture of The Pig.
Latin-pig
To analyze data using Pig, programmers write scripts in Pig Latin. Grunt Shell is the virtual shell of Pig, which is used to run all Pig scripts. If a Pig script is written in a script file, it is executed by the Pig Server. The Pig script syntax is tested by the parser, after which the output will be a DAG (Directed Acyclic Graph). To the logical optimizer, the DAG (logical plan) is transmitted. The DAG is translated into MapReduce jobs by the compiler. The Execution Engine then runs the MapReduce work. The results are shown using the “DUMP” statement and stored using the “Inventory” statement in HDFS.
Hive is next up on the language list.
The Hive
To facilitate the reading, writing, and management of large datasets residing in distributed storage, Hive utilizes SQL (Structured Query Language). As users were familiar with writing queries in SQL, the hive was built with a vision of combining the concepts of tables and columns with SQL.
There are two main components of the Apache Hive.
- Control Line of Hive
- Driver for JDBC/ ODBC
The application for Java Database Connectivity (JDBC) is connected via the JDBC driver, and the application for Open Database Connectivity (ODBC) is connected via the ODBC Driver. In CLI, commands are executed directly. For all the queries sent, the Hive driver is responsible for performing the three stages of internal compilation, optimization, and execution. To process questions, it then uses the MapReduce system.
The Hive architecture is presented below:
Spark
In and of itself, Spark is an immense platform, an open-source distributed computing system for the collection and analysis of massive real-time data volumes. It runs faster than MapReduce 100 times. Spark offers an in-memory data calculation that is used, among other items, to process and analyze real-time streaming data such as stock market and banking data.
The Master Node has a driver program, as seen from the above picture. As a driver application, the Spark code works and generates a SparkContext, which is a portal to all Spark functionalities. Spark applications operate on the cluster as separate sets of processes. Inside the cluster, the driver software and Spark background take care of the job execution. A job is divided into several tasks spread over the worker node. It can be spread across different nodes when an RDD is generated in the Spark sense. Worker nodes are slaves with various tasks going. The completion of these activities is the responsibility of the Executor. Worker nodes perform Cluster Manager assigned tasks and return the results to the Spark Context.
Let us now switch to the Hadoop Machine Learning area and its numerous permutations.
Mahout
Mahout is used to constructing machine learning algorithms that are scalable and distributed, such as clustering, linear regression, classification, and so on. It has a library for collaborative filtering, grouping, and clustering that includes built-in algorithms.
Ambari
We’ve got Apache Ambari next up. It is an open-source tool that keeps track of the applications running and their status. Hadoop clusters are managed, tracked, and provisioned by Ambari. Also, to start, stop, and configure Hadoop services, it offers a central management service.
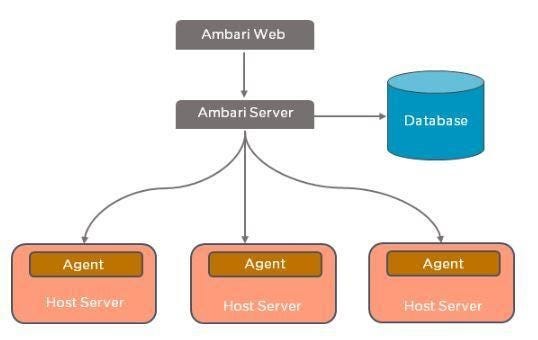
The Ambari Site, which is your interface, is linked to the Ambari server, as shown in the following image. Apache Ambari meets an architectural master/slave. To keep track of the state of the infrastructure, the master node is responsible. The master node uses a database server that can be configured during the period of configuration to do this. The Ambari server is most frequently located on the MasterNode and linked to the database. This is where the host server is looked at by officers. Agents run on all the nodes under Ambari that you want to control. Occasionally, this program sends heartbeats to the master node to demonstrate its aliveness. Ambari Server is able to perform several tasks by using Ambari Agent.
Conclusion
I hope you reach to a conclusion about the Hadoop Ecosystem and tools. You can learn more through big data online training



No comments: