
Understand the process of configuring Spark Application
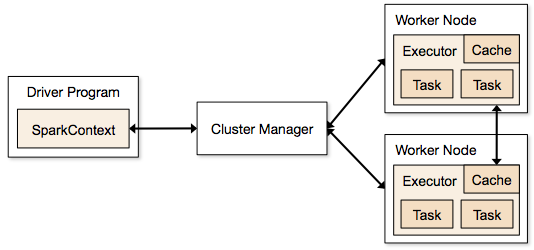
Apache Spark is a powerful open-source analytics engine with a distributed general-purpose cluster computing framework. Spark Application is a self-contained computation that includes a driver process and a set of executor processes. Here, the driver process runs the main() function by sitting upon a node within the cluster. Moreover, this is responsible for three things: managing information regarding the Spark application; responding to a user’s program or input; and analyzing, allocating, and planning work across the executors.
The driver process is completely essential and it’s considered as the heart of a Spark application. It also manages all pertinent information during the lifetime of the Spark application. Furthermore, the executors are mainly responsible for actually executing the work that the driver allocates them.
Furthermore, Spark application can be configured using various properties that could be set directly on a SparkConf object. And the same is passed while initializing SparkContext,More info visit:big data and hadoop online training
Spark configuration
The below mentioned are the properties & their descriptions. This can be useful to tune and fit a spark application within the Apache Spark environment. Hereunder, we will discuss the following properties with particulars and examples:
- Apache Spark Application Name
- Number of Apache Spark Driver Cores
- Driver’s Maximum Result Size
- Driver’s Memory
- Executors’ Memory
- Spark’s Extra Listeners
- Local Directory
- Log Spark Configuration
- Spark Master
- Deploy Mode of Spark Driver
- Log App Information
- Spark Driver Supervise Action
Set Spark Application Name
The below code snippet helps us to understand the setting up of “Application Name”.
import org.apache.spark.SparkConf;
import org.apache.spark.SparkContext;
/**
* Configure Apache Spark Application Name
*/
public class AppConfigureExample {
public static void main(String[] args) {
// configure spark
SparkConf conf = new SparkConf().setMaster("local[2]");
conf.set("spark.app.name", "SparkApplicationName");
// start a spark context
SparkContext sc = new SparkContext(conf);
// print the configuration
System.out.println(sc.getConf().toDebugString());
// stop the spark context
sc.stop();
}
}
Output
Besides, the result for the above program is as follows;
spark.app.id=local-1501222987079
spark.app.name=SparkApplicationName
spark.driver.host=192.168.1.100
spark.driver.port=44103
spark.executor.id=driver
spark.master=local[2]
Number of Spark Driver Cores
Here, we will check the amount of Spark driver cores;
- Name of the Property: spark.driver.cores
- Default value: 01
- Exception: This property is considered only within-cluster mode.
Moreover, this point renders the max number of cores that a driver process may use.
The below example explains to set the number of spark driver cores.
Set Spark Driver Cores
import org.apache.spark.SparkConf;
import org.apache.spark.SparkContext;
public class AppConfigureExample {
public static void main(String[] args) {
// configure spark
SparkConf conf = new SparkConf().setMaster("local[2]");
conf.set("spark.app.name", "SparkApplicationName");
conf.set("spark.driver.cores", "2");
// start a spark context
SparkContext sc = new SparkContext(conf);
// print the configuration
System.out.println(sc.getConf().toDebugString());
// stop the spark context
sc.stop();
}
}
Output
We can see the below output for the above code given.
spark.app.id=local-1501223394277
spark.app.name=SparkApplicationName
spark.driver.cores=2
spark.driver.host=192.168.1.100
spark.driver.port=42100
spark.executor.id=driver
spark.master=local[2]
Driver’s Maximum Result Size
Here, we will go with the Driver’s result size.
- Name of the property: spark.driver.maxResultSize
- Default value: 1 GB
- Exception: Min value 1MB
This is the maximum limit on the total sum of size of serialized results of all partitions for each Spark action. Submitted jobs will stop in case the limit exceeds. By setting it to ‘zero’ means, there is no maximum limitation here to use. But, in case the value set by the property get exceeds, out-of-memory may occur within driver. The following is an example to set Maximum limit on Spark Driver’s memory usage:
Set Maximum limit on Spark Driver's memory usage
import org.apache.spark.SparkConf;
import org.apache.spark.SparkContext;
public class AppConfigureExample {
public static void main(String[] args) {
// configure spark
SparkConf conf = new SparkConf().setMaster("local[2]");
conf.set("spark.app.name", "SparkApplicationName");
conf.set("spark.driver.maxResultSize", "200m");
// start a spark context
SparkContext sc = new SparkContext(conf);
// print the configuration
System.out.println(sc.getConf().toDebugString());
// stop the spark context
sc.stop();
}
}
Output
This is the result that we get from the input given,
spark.app.id=local-1501224103438
spark.app.name=SparkApplicationName
spark.driver.host=192.168.1.100
spark.driver.maxResultSize=200m
spark.driver.port=35249
spark.executor.id=driver
spark.master=local[2]
Driver’s Memory Usage
- Property Name : spark.driver.memory
- Default value: Its 1g or 1 GB
- Exception: In case, the spark application is yielded in client mode, the property has to be set through the command line option –driver-memory.
The following is the maximum limit on the usage of memory by Spark Driver. Submitted tasks may abort in case the limit exceeds. Setting it to ‘Zero’ means, there is no upper limit to use memory. But, in case the value set by the property exceeds, out-of-memory may occur within the driver. The below example explains how to set the Max limit on Spark Driver’s memory usage:
Set Maximum limit on Spark Driver's memory usage
import org.apache.spark.SparkConf;
import org.apache.spark.SparkContext;
public class AppConfigureExample {
public static void main(String[] args) {
// configure spark
SparkConf conf = new SparkConf().setMaster("local[2]");
conf.set("spark.app.name", "SparkApplicationName");
conf.set("spark.driver.memory", "600m");
// start a spark context
SparkContext sc = new SparkContext(conf);
// print the configuration
System.out.println(sc.getConf().toDebugString());
// stop the spark context
sc.stop();
}
}
Output
The resulting output will be as follows.
spark.app.id=local-1501225134344
spark.app.name=SparkApplicationName
spark.driver.host=192.168.1.100
spark.driver.memory=600m
spark.driver.port=43159
spark.executor.id=driver
spark.master=local[2]
Spark executor memory
Within every spark application there exist the same fixed stack size and a fixed number of cores for a spark executor also. The stack size refers to the Spark executor memory and the same is controlled with the spark.executor.memory property under the –executor-memory flag. Moreover, each spark application includes a single executor on each worker node. The executor memory is generally an estimate on how much memory of the worker node may the application will use.
Spark Extra Listeners
Users can utilize extra listeners by setting them under the spark.extraListeners property. The spark.extraListeners property is a comma-separated list of classes that deploy SparkListener. While starting SparkContext, instances of these classes will be developed and registered with Spark's listener bus (SLB).
In addition, to add extra listeners to the Spark application, users have the option to set this property during the usage of the spark-submit command. An example of it is:
./bin/spark-submit --conf spark.extraListereners <Comma-separated list of listener classes>
Local Directory
The directory useful for "scratch" space in the Spark application includes map output files and RDDs that stored on the disk. Moreover, this should be on a fast, local disk within the user’s system. This could be also a comma-separated (CSV) list of various directories on multiple disks.
Log Spark Configuration
In Spark configuration, “Logs” are the effective SparkConf as INFO while a SparkContext starts.
Spark Master
In this, the master URL has to use for the cluster connection purpose.
Deploy Mode of Spark Driver
The deploy mode of the Spark driver program within the Spark Application configuration, either client or cluster. This means to launch/start the driver program locally ("client") or remotely upon one of the nodes within the cluster.
There are two final steps in this regard namely; Log App Information and Spark Driver Supervise Action. These include logging in the info of the application while configuring and supervising the driver’s action.
Thus, in short, we can say that the whole process starts with a Spark Driver. Here, the Spark driver is accountable for changing a user program into units of physical performance known as tasks. At a high level, all the Spark programs follow a similar structure to perform well. Moreover, they built RDDs from some input to obtain new RDDs from those using transformations. And they execute actions to gather or save data. A Spark program completely builds a logical directed acyclic graph (DAG) of operations/processes.
Bottom Line
I hope you got the basic idea of the process of configuring Spark Application. This may help you to understand the further process easily with advanced options. Get more insights from big data online training



No comments: