
Definition Of MapReduce In hadoop
What is MapReduce?
MapReduce is a patented software framework introduced by Google to support distributed computing on large data sets on clusters of computers.
MapReduce is a functional programming model. It runs in the Hadoop background to provide scalability, simplicity, speed, recovery and easy solutions for data processing.
Why MapReduce?
Normally traditional enterprise system used centralized processing server to store and process data. This system is not suitable to process large volumes of data. If we are trying to process multiple files concurrently, then the centralized system creates too much of a bottleneck. Google gave the solution to this bottleneck issue by using an algorithm known as MapReduce.
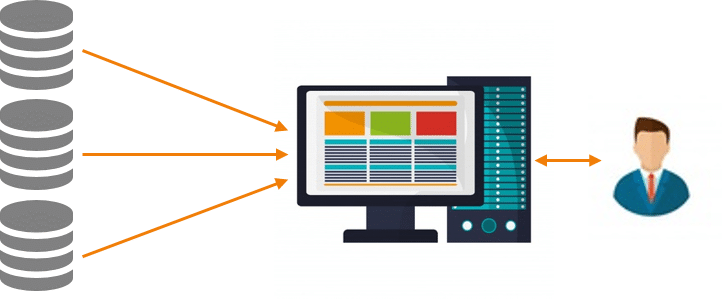
In the MapReduce process the large tasks are split into smaller tasks, and then they are assigned to many systems.
Ways to MapReduce
Libraries : Hbase, Hive, Pig, Sqoop, Oozie, Mahout and others
Languages : Java *, HiveQL (HQL) , Pig Latin, Python, C#, Javascript, R and more.



{kind=link}
No comments: