
Apache Spark Architecture Explained in Detail
Apache Spark is considered as a powerful complement to Hadoop, big data’s original technology of choice. Spark is a more accessible, powerful and capable big data tool for tackling various big data challenges. With more than 500 contributors from across 200 organizations responsible for code and a user base of 225,000+ members- Apache Spark has become mainstream and most in-demand big data framework across all major industries. Ecommerce companies like Alibaba, social networking companies like Tencent and chines search engine Baidu, all run apache spark operations at scale. This article is
a single-stop resource that gives spark architecture overview with the help of spark architecture diagram and is a good beginners resource for people looking to learn spark.
To more tutorials visit OnlineITguru big data online course Blog
Understanding Apache Spark Architecture

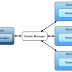
Spark Architecture Diagram – Overview of Apache Spark Cluster
Apache Spark has a well-defined and layered architecture where all the spark components and layers are loosely coupled and integrated with various extensions and libraries. Apache Spark Architecture is based on two main abstractions-
- Resilient Distributed Datasets (RDD)
- Directed Acyclic Graph (DAG)
Resilient Distributed Datasets (RDD)
RDD’s are collection of data items that are split into partitions and can be stored in-memory on workers nodes of the spark cluster. In terms of datasets, apache spark supports two types of RDD’s – Hadoop Datasets which are created from the files stored on HDFS and parallelized collections which are based on existing Scala collections. Spark RDD’s support two different types of operations – Transformations and Actions.
Directed Acyclic Graph (DAG)
Direct - Transformation is an action which transitions data partition state from A to B.
Acyclic -Transformation cannot return to the older partition
DAG is a sequence of computations performed on data where each node is an RDD partition and edge is a transformation on top of data. The DAG abstraction helps eliminate the Hadoop MapReduce multi0stage execution model and provides performance enhancements over Hadoop.
Spark Architecture Overview
Apache Spark follows a master/slave architecture with two main daemons and a cluster manager –
- Master Daemon – (Master/Driver Process)
- Worker Daemon –(Slave Process)
A spark cluster has a single Master and any number of Slaves/Workers. The driver and the executors run their individual Java processes and users can run them on the same horizontal spark cluster or on separate machines i.e. in a vertical spark cluster or in mixed machine configuration.
Role of Driver in Spark Architecture
Spark Driver – Master Node of a Spark Application
It is the central point and the entry point of the Spark Shell (Scala, Python, and R). The driver program runs the main () function of the application and is the place where the Spark Context is created. Spark Driver contains various components – DAGScheduler, TaskScheduler, BackendScheduler and BlockManager responsible for the translation of spark user code into actual spark jobs executed on the cluster.
- The driver program that runs on the master node of the spark cluster schedules the job execution and negotiates with the cluster manager.
- It translates the RDD’s into the execution graph and splits the graph into multiple stages.
- Driver stores the metadata about all the Resilient Distributed Databases and their partitions.
- Cockpits of Jobs and Tasks Execution -Driver program converts a user application into smaller execution units known as tasks. Tasks are then executed by the executors i.e. the worker processes which run individual tasks.
- Driver exposes the information about the running spark application through a Web UI at port 4040.
Role of Executor in Spark Architecture
Executor is a distributed agent responsible for the execution of tasks. Every spark applications has its own executor process. Executors usually run for the entire lifetime of a Spark application and this phenomenon is known as “Static Allocation of Executors”. However, users can also opt for dynamic allocations of executors wherein they can add or remove spark executors dynamically to match with the overall workload.
- Executor performs all the data processing.
- Reads from and Writes data to external sources.
- Executor stores the computation results data in-memory, cache or on hard disk drives.
- Interacts with the storage systems.
Role of Cluster Manager in Spark Architecture
An external service responsible for acquiring resources on the spark cluster and allocating them to a spark job. There are 3 different types of cluster managers a Spark application can leverage for the allocation and deallocation of various physical resources such as memory for client spark jobs, CPU memory, etc. Hadoop YARN, Apache Mesos or the simple standalone spark cluster manager either of them can be launched on-premise or in the cloud for a spark application to run.
Choosing a cluster manager for any spark application depends on the goals of the application because all cluster managers provide different set of scheduling capabilities. To get started with apache spark, the standalone cluster manager is the easiest one to use when developing a new spark application.
Understanding the Run Time Architecture of a Spark Application
What happens when a Spark Job is submitted?
When a client submits a spark user application code, the driver implicitly converts the code containing transformations and actions into a logical directed acyclic graph (DAG). At this stage, the driver program also performs certain optimizations like pipelining transformations and then it converts the logical DAG into physical execution plan with set of stages. After creating the physical execution plan, it creates small physical execution units referred to as tasks under each stage. Then tasks are bundled to be sent to the Spark Cluster.
The driver program then talks to the cluster manager and negotiates for resources. The cluster manager then launches executors on the worker nodes on behalf of the driver. At this point the driver sends tasks to the cluster manager based on data placement. Before executors begin execution, they register themselves with the driver program so that the driver has holistic view of all the executors. Now executors start executing the various tasks assigned by the driver program. At any point of time when the spark application is running, the driver program will monitor the set of executors that run. Driver program in the spark architecture also schedules future tasks based on data placement by tracking the location of cached data. When driver programs main () method exits or when it call the stop () method of the Spark Context, it will terminate all the executors and release the resources from the cluster manager.
For big data hadoop training visit the following Blog.



No comments: