
Hive and impala for managing structured Data
Big Data is the area of study in which vast quantities of data are collected, analyzed to create predictive
models, and support the company in the process. The data used over here is often unstructured, and it's
huge in quantity. Such data which encompasses the definition of volume , velocity, veracity, and variety
is known as Big Data.
Hadoop and Spark are two of the most popular open-source frameworks used to deal with big data. The
Hadoop architecture contains the following .
● HDFS:
Hdfs is the storage mechanism. It stores the big data across multiple clusters.
● Map Reduce:
You can process data using a programming model known as Map Reduce.
● Yarn :
It manages resources required for the data processing.
● Ozzie
A scheduling system to manage Hadoop jobs.
● Mahout
For Machine Learning operations in Hadoop, the Mahout framework is used.
● Pig
Executes Map Reduce programs. It allows the flow of programs which are higher level.
● Flume
Used for streaming data into the Hadoop platform.
● Sqoop
The data transfer between Hadoop Distributed File System, and the Relational Database
Management system is facilitated by Apache Sqoop.
● Hbase
A database management system which is column oriented, and works best with sparse data
sets.
● Hive
It allows data manipulation in Hadoop to run SQL like database operations.
● Impala
It 's a data processing SQL database engine, but it operates better than Hive.
There are various Hadoop modules with their own special functionalities.
Managing structured data with Hive and Impala
Before getting into that let us see briefly about Hive and Impala.
models, and support the company in the process. The data used over here is often unstructured, and it's
huge in quantity. Such data which encompasses the definition of volume , velocity, veracity, and variety
is known as Big Data.
Hadoop and Spark are two of the most popular open-source frameworks used to deal with big data. The
Hadoop architecture contains the following .
● HDFS:
Hdfs is the storage mechanism. It stores the big data across multiple clusters.
● Map Reduce:
You can process data using a programming model known as Map Reduce.
● Yarn :
It manages resources required for the data processing.
● Ozzie
A scheduling system to manage Hadoop jobs.
● Mahout
For Machine Learning operations in Hadoop, the Mahout framework is used.
● Pig
Executes Map Reduce programs. It allows the flow of programs which are higher level.
● Flume
Used for streaming data into the Hadoop platform.
● Sqoop
The data transfer between Hadoop Distributed File System, and the Relational Database
Management system is facilitated by Apache Sqoop.
● Hbase
A database management system which is column oriented, and works best with sparse data
sets.
● Hive
It allows data manipulation in Hadoop to run SQL like database operations.
● Impala
It 's a data processing SQL database engine, but it operates better than Hive.
There are various Hadoop modules with their own special functionalities.
Managing structured data with Hive and Impala
Before getting into that let us see briefly about Hive and Impala.
Hive
Apache Hive is an open-source Hadoop application data warehouse framework for data summarization
and analysis, and for querying massive data structures. It transforms SQL-like queries into MapReduce
jobs to make incredibly large amounts of data easy to execute and process.
Impala
One method that you use to solve Hive Queries slowness is what we call Impala. An independent
method was supplied by distribution. Syntactically Impala queries run much faster than Hive Queries
even after they are more or less the same as Hive Queries themselves.
It provides low-latency , high-performance SQL queries. Impala is the best choice when dealing with
medium-sized datasets and we expect our queries to provide the real-time response. But make sure that
Impala is only available in Hadoop distribution.
Apache Hive is an open-source Hadoop application data warehouse framework for data summarization
and analysis, and for querying massive data structures. It transforms SQL-like queries into MapReduce
jobs to make incredibly large amounts of data easy to execute and process.
Impala
One method that you use to solve Hive Queries slowness is what we call Impala. An independent
method was supplied by distribution. Syntactically Impala queries run much faster than Hive Queries
even after they are more or less the same as Hive Queries themselves.
It provides low-latency , high-performance SQL queries. Impala is the best choice when dealing with
medium-sized datasets and we expect our queries to provide the real-time response. But make sure that
Impala is only available in Hadoop distribution.
For Complete big data hadoop course visit OnlineITGuru Website
Tables in Hive and Impala
A table is simply an HDFS directory that includes zero files or more.
Path by default: /user / hive / warehouse/<table name >
A table for handling Hive and Impala data is given below.
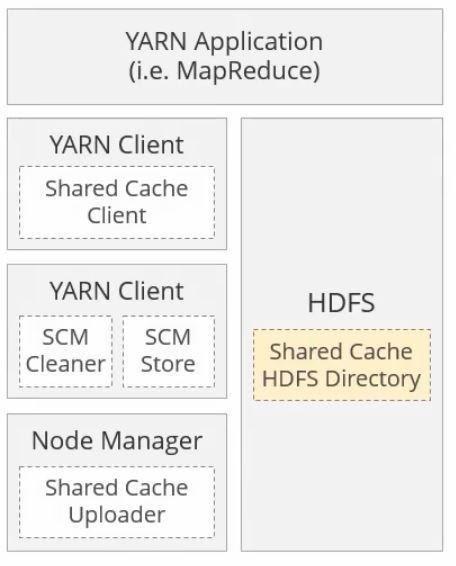
Table managing data with hive and impala
The table supports many data storage and retrieval formats. The metadata generated is stored in the Hive Metastore and is used in an RDBMS such as MySQL.
Hive and Impala work on the same data-HDFS tables, Metastore metadata.
Let's get into what Hive Metastore is.
Hive MetaStore
The Metastore is a Hive component that stores tables, columns, and partitions that create the device catalog containing metadata about Hive. Metadata is normally stored in traditional RDBMS format.
Apache Hive however uses the Derby database to store metadata by default. Some access to Java Server or JDBC-compliant servers such as MySQL may be used to build a Hive Metastore.
Hive Metastore needs to have a range of primary attributes installed. Any of them include.
- Link URL
- Connecting rider
- Link to User ID
- Connecting Password
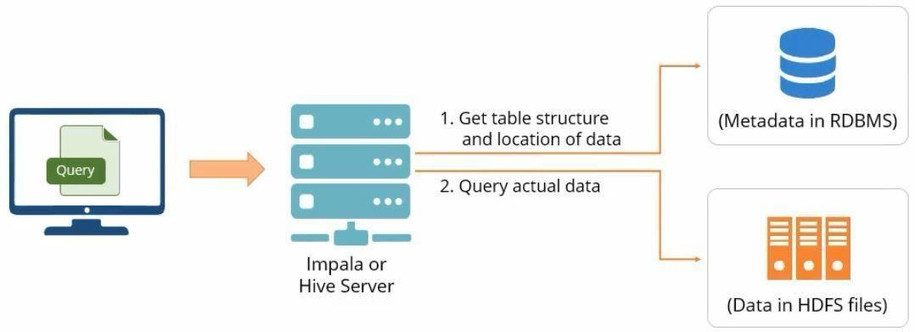
Metastore in Hive and Impala
Hive and Impala servers use Metastore to obtain table structure and position of the data. As shown in the diagram below, the query is sent to the Hive Or Impala server first and then the query reaches the Metastore to get the table structure and the location of the data.
Use-of-metastore in hive and impala
Once the query receives the information required, the server will query the actual data on the table in the HDFS.
Now that you have looked at using Metastore in Hive and Impala, we 're going to talk about how and where the data gets stored in the Hive table.
Structure of data center registry in Hive and impala
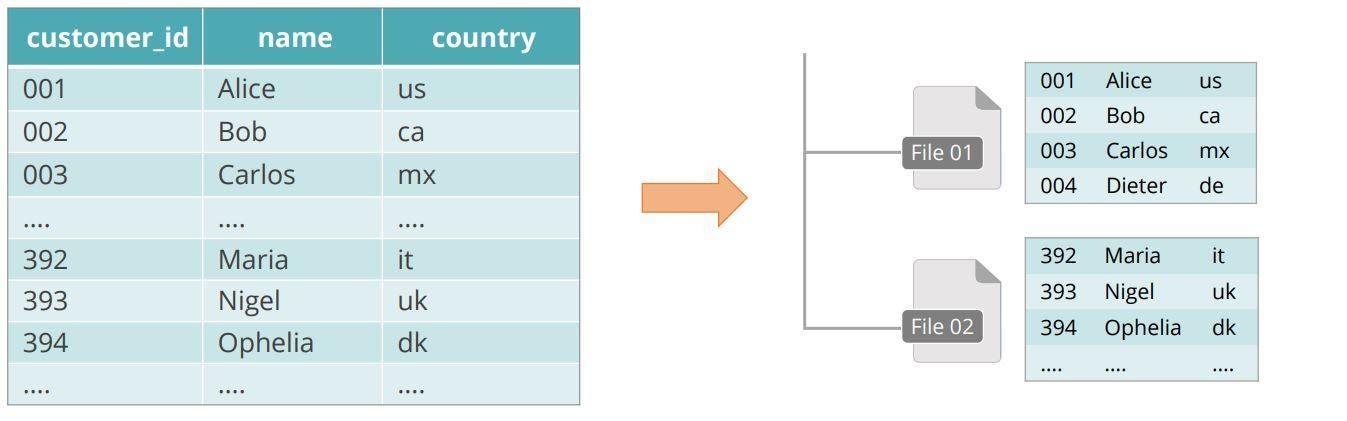
All data is stored in: /user / hive / warehouse by default.
Every table is a directory containing one or more files within its default location. As shown below, the table for hive customers is.
As shown in the diagram, the Hive customer table stored can be viewed as follows.
The Hive customer table stores data in the default HDFS directory creating a directory called "customers."
Defining Tables and Databases in Hive and impala
In this section, along with the steps involved in creating a table, you'll learn how to identify, build and delete a database.
Databases and tables are created and managed using the HiveQL or Impala SQL (Data Definition Language) DDL which is very similar to standard SQL DDL. You can notice minor differences when writing HiveQL and Impala SQL DDL operations.
Now that you've learned the way a database is described, let 's discuss how to construct a database.
Creation of a Hive Database
You need to publish, to build a new database:
Data base name CREATE DATABASE
To prevent an error in the event that the database already exists, write.
Build DATABASE IF Datenbank NOT EXISTS
Eliminating a Folder
Removing a database is a lot like creating a database. Develop should be replaced with DROP as follows.
DROP NAME DATABASE;
You should type in: if the database already exists:
DROP DATABASE IF the database name for the exists;
To delete a database if it already has tables, attach the word CASCADE to the query. The database will be forcefully removed.
DROP Simplifying DATABASE CASCADE;
Note: This could erase data from HDFS.
Now let's go into the CREATE TABLE syntax in detail. Let's look now at how you can build a table in Hive.
Hive-Build Table
The first line of code consists of:
Build TABLE tablename (DATA TYPES colnames)
Specify table name and column name list and DATATYPES list.
The code's second line, is:
DELIMITED FORMAT ROW
It states that fields are delimited by some character in each file in the table directory. Control-a is the default delimiter but you can specify an alternative delimiter.
The code 's third line, is:
TERMINATED FIELDS Of char
This specifies termination of any data sector.
Tab-delimited data , for example, will allow you to define fields terminated by,/t.
Use the last line of code to:
STOREAS FILE {TEXT OR SEQUENCEFILE}
You will declare the format of the file to be stored as a text file that is the default and need not be specified. The syntax for creating a new table is as shown below.
Syntax-to-create-new-tableSyntax establishes a subdirectory in the HDFS Warehouse Database directory. The table will be stored in the default HDFS position for the standard database.
Within the default HDFS folder, a directory with the data name.db name will be created for the named database format and the table will be saved into that directory.
Conclusion
I hope you reach to a conclusion about Hive and impala for handling structured data. You can learn more through experts through big data online course.



No comments: