
Concepts of Hadoop and installing it in Hadoop cluster environment
Apache Hadoop is one of the open-source software most commonly used to make sense of Big Data.
Every company needs to make sense of the data on an ongoing basis in today's digitally powered world.
Hadoop is a whole ecosystem of Big Data resources and technologies, commonly used to store and
process big data.
Every company needs to make sense of the data on an ongoing basis in today's digitally powered world.
Hadoop is a whole ecosystem of Big Data resources and technologies, commonly used to store and
process big data.
To learn more tutorials visit OnlineITGuru's blog big data and hadoop course
The architecture can be split into two parts, i.e. the core components of Hadoop and the
complementary or other components.
Architecture of a Hadoop
There are four main or basic components.
● Hadoop Common:
This is a compilation of common utilities and libraries that manage other modules in Hadoop. This
ensures the Hadoop cluster automatically handles the hardware failures.
● HDFS:
It is a Hadoop Distributed File System that stores and distributes data over the Hadoop cluster in the
form of small memory blocks. To ensure consistency of the data, each data is repeated several times.
● Hadoop YARN:
It allocates resources that in turn allow different users to execute different applications without
worrying about the increased workloads.
● Hadoop MapReduce:
By spreading the data as small blocks, it performs tasks in parallel fashion.
Additional or Other Hadoop Elements
Ambari:
Ambari is a web-based platform for the management, configuration and testing of Big Data Hadoop
clusters to support components like HDFS, MapReduce, Hive, HCatalog, HBase, ZooKeeper, Oozie, Pig
and Sqoop. It offers a Hadoop cluster health monitoring console as well as allows user-friendly
assessment of the performance of certain components including MapReduce, Pig, Hive, etc.
Cassandra:
This is an open-source, highly scalable distributed NoSQL-based database system dedicated to managing
large quantities of data across numerous commodity servers, eventually leading to high availability
without a single fail.
Flume:
Flume is a distributed and secure tool to collect, consolidate and efficiently transfer the bulk of
streaming data into HDFS.
HBase:
HBase is a distributed, non-relational database running on the Big Data Hadoop Hadoop cluster, which
stores vast volumes of structured data. It serves as an input for jobs in MapReduce.
HCatalog:
It's a table and storage management layer that allows developers to access and exchange data.
Hive:
Hive is a data storage platform allowing data to be compiled, queried, and analyzed using a SQL-like
query language.
Oozie:
Oozie is a server-based program that handles the Hadoop jobs and schedules them.
Pig:
A dedicated high-level tool, Pig is in charge of manipulating data stored in HDFS with the aid of a
MapReduce compiler and a language named Pig Latin. It helps analysts to collect, transform , and load
the data (ETL) without MapReduce writing codes.
Solr:
A search method that can be highly scaled, Solr allows indexing, central setup, failures and recovery.
Spark:
An open source fast engine responsible for SQL streaming and supporting Hadoop, machine learning and
graph processing.
Sqoop:
It's a system between Hadoop and organized databases to move massive quantities of data.
large quantities of data across numerous commodity servers, eventually leading to high availability
without a single fail.
Flume:
Flume is a distributed and secure tool to collect, consolidate and efficiently transfer the bulk of
streaming data into HDFS.
HBase:
HBase is a distributed, non-relational database running on the Big Data Hadoop Hadoop cluster, which
stores vast volumes of structured data. It serves as an input for jobs in MapReduce.
HCatalog:
It's a table and storage management layer that allows developers to access and exchange data.
Hive:
Hive is a data storage platform allowing data to be compiled, queried, and analyzed using a SQL-like
query language.
Oozie:
Oozie is a server-based program that handles the Hadoop jobs and schedules them.
Pig:
A dedicated high-level tool, Pig is in charge of manipulating data stored in HDFS with the aid of a
MapReduce compiler and a language named Pig Latin. It helps analysts to collect, transform , and load
the data (ETL) without MapReduce writing codes.
Solr:
A search method that can be highly scaled, Solr allows indexing, central setup, failures and recovery.
Spark:
An open source fast engine responsible for SQL streaming and supporting Hadoop, machine learning and
graph processing.
Sqoop:
It's a system between Hadoop and organized databases to move massive quantities of data.
ZooKeeper:
ZooKeeper configures and synchronizes the distributed systems with an open source program.
Install Hadoop in Hadoop cluster environment
You can learn about Downloading Hadoop in this segment. You need to first download Hadoop which is
an open-source tool to function in the Hadoop environment. Hadoop installation can be performed free
of charge on any system, as the software is available as an open source resource. There are however
some device specifications that need to be met for an effective installation of the Hadoop application
such as.
ZooKeeper configures and synchronizes the distributed systems with an open source program.
Install Hadoop in Hadoop cluster environment
You can learn about Downloading Hadoop in this segment. You need to first download Hadoop which is
an open-source tool to function in the Hadoop environment. Hadoop installation can be performed free
of charge on any system, as the software is available as an open source resource. There are however
some device specifications that need to be met for an effective installation of the Hadoop application
such as.
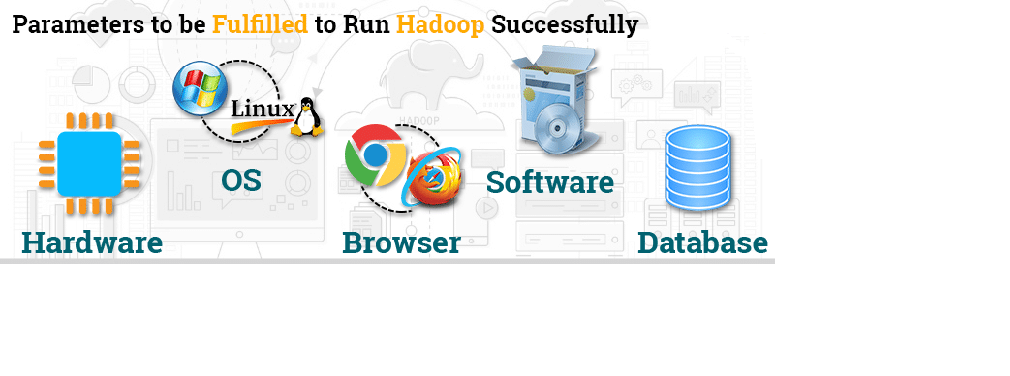
Hardware Claims:
Hadoop can operate on any single Hadoop cluster of hardware. All you need is some hardware on
commodities.
OS Prerequisite:
Hadoop can run on UNIX and Windows systems, when it comes to the operating system. Linux is the
only framework used for the specifications of the goods.
Request for Browser:
When it comes to browsers, Hadoop supports most popular browsers with ease. Depending on the
need, these browsers include Microsoft Internet Explorer, Mozilla Firefox, Google Chrome, Windows
Safari, and Macos and Linux systems.
Computer Prerequisite:
Hadoop 's main prerequisite is the Java main, since the Hadoop application is written primarily in Java
programming language. The lowest version for Android is version Java 1.6.
Hadoop can operate on any single Hadoop cluster of hardware. All you need is some hardware on
commodities.
OS Prerequisite:
Hadoop can run on UNIX and Windows systems, when it comes to the operating system. Linux is the
only framework used for the specifications of the goods.
Request for Browser:
When it comes to browsers, Hadoop supports most popular browsers with ease. Depending on the
need, these browsers include Microsoft Internet Explorer, Mozilla Firefox, Google Chrome, Windows
Safari, and Macos and Linux systems.
Computer Prerequisite:
Hadoop 's main prerequisite is the Java main, since the Hadoop application is written primarily in Java
programming language. The lowest version for Android is version Java 1.6.
Requirement Database:
Hive or HCatalog includes a MySQL database within the Hadoop ecosystem for successful operation of
the Hadoop framework. You can run the latest version directly, or let Apache Ambari decide on the
wizard required for the same.
Styles of Setup in Hadoop cluster
There are different ways Hadoop can be run in. Below are the scenarios you can download, install, and
run Hadoop clusters.
Autonomous Mode
Although Hadoop is a distributed platform for working with Big Data, in one single standalone instance
you can even install Hadoop on a single node. The entire Hadoop framework thus behaves like a system
running on Java. This is often used for debugging purposes. It helps if you want to test your MapReduce
apps on a single node before you run on a massive Hadoop cluster.
Completely Shared Mode
This is a distributed mode, which has several commodity hardware nodes connected to form the
Hadoop cluster of Hadoop. The NameNode, JobTracker, and Secondary NameNode operate on the
master node in such a configuration, while the DataNode, and the Secondary DataNode operate on the
slave node. The other pair of nodes operate on the slave node, namely, the DataNode and the
TaskTracker.
Pseudo Spread mode
It is, in essence, a Java single-node framework running the entire Hadoop cluster. So, various daemons
including NameNode, DataNode, TaskTracker, and JobTracker run to form the distributed Hadoop
cluster on the Java machine's single case.
Ecosystem: Hadoop
The Hadoop ecosystem includes numerous components, such as Apache Hive, Pig, Sqoop, and
ZooKeeper. Various roles are different on each of these components. Hive is a dialect of SQL primarily
used to summarize, query, and analyze data. Pig is a data flow language used for abstraction in order to
simplify the MapReduce tasks for those who don't know how to code MapReduce applications in Java.
Hadoop Example: The Word Count
The example of Word Count is the most important example of the domain Hadoop. Here, using
MapReduce we find out the frequency of every word in a text. The Mapper 's role is to map the keys to
Hive or HCatalog includes a MySQL database within the Hadoop ecosystem for successful operation of
the Hadoop framework. You can run the latest version directly, or let Apache Ambari decide on the
wizard required for the same.
Styles of Setup in Hadoop cluster
There are different ways Hadoop can be run in. Below are the scenarios you can download, install, and
run Hadoop clusters.
Autonomous Mode
Although Hadoop is a distributed platform for working with Big Data, in one single standalone instance
you can even install Hadoop on a single node. The entire Hadoop framework thus behaves like a system
running on Java. This is often used for debugging purposes. It helps if you want to test your MapReduce
apps on a single node before you run on a massive Hadoop cluster.
Completely Shared Mode
This is a distributed mode, which has several commodity hardware nodes connected to form the
Hadoop cluster of Hadoop. The NameNode, JobTracker, and Secondary NameNode operate on the
master node in such a configuration, while the DataNode, and the Secondary DataNode operate on the
slave node. The other pair of nodes operate on the slave node, namely, the DataNode and the
TaskTracker.
Pseudo Spread mode
It is, in essence, a Java single-node framework running the entire Hadoop cluster. So, various daemons
including NameNode, DataNode, TaskTracker, and JobTracker run to form the distributed Hadoop
cluster on the Java machine's single case.
Ecosystem: Hadoop
The Hadoop ecosystem includes numerous components, such as Apache Hive, Pig, Sqoop, and
ZooKeeper. Various roles are different on each of these components. Hive is a dialect of SQL primarily
used to summarize, query, and analyze data. Pig is a data flow language used for abstraction in order to
simplify the MapReduce tasks for those who don't know how to code MapReduce applications in Java.
Hadoop Example: The Word Count
The example of Word Count is the most important example of the domain Hadoop. Here, using
MapReduce we find out the frequency of every word in a text. The Mapper 's role is to map the keys to
existing values, and the reducer 's role is to aggregate the common values keys. So, it's all expressed as a
key – value pair.
You can install Hadoop for operating according to the big data processing needs in various types of
setups.
Big Commands on Hadoop
Hadoop has many file system commands that communicate directly with the distributed Hadoop file
system to get the necessary results.
● AddToFile
● Checkpoint
● ToLocalCopy
● MoveToLocal
● CHARGE
Above are some of the most common commands that Hadoop uses to perform different tasks within its
system.
Hadoop Streaming
The popular API used to deal with streaming data is hadoop streaming. Within a regular format, both
the Mapper and the Reducer get their inputs. Stdin's input is taken, and the output is sent to Stdout. It is
the framework for manipulating continuous data streams within Hadoop.
Hadoop is the framework used for the collection and storage of Big Data. Hadoop creation is the job of
computing Big Data by using various programming languages like Java, Scala and others. Hadoop
supports a variety of types of data, such as boolean, char, array, decimal, string, float, double, etc.
Conclusion
I hope you reach a conclusion about Hadoop architecture components and installation. You can learn
more through big data hadoop training.
key – value pair.
You can install Hadoop for operating according to the big data processing needs in various types of
setups.
Big Commands on Hadoop
Hadoop has many file system commands that communicate directly with the distributed Hadoop file
system to get the necessary results.
● AddToFile
● Checkpoint
● ToLocalCopy
● MoveToLocal
● CHARGE
Above are some of the most common commands that Hadoop uses to perform different tasks within its
system.
Hadoop Streaming
The popular API used to deal with streaming data is hadoop streaming. Within a regular format, both
the Mapper and the Reducer get their inputs. Stdin's input is taken, and the output is sent to Stdout. It is
the framework for manipulating continuous data streams within Hadoop.
Hadoop is the framework used for the collection and storage of Big Data. Hadoop creation is the job of
computing Big Data by using various programming languages like Java, Scala and others. Hadoop
supports a variety of types of data, such as boolean, char, array, decimal, string, float, double, etc.
Conclusion
I hope you reach a conclusion about Hadoop architecture components and installation. You can learn
more through big data hadoop training.



No comments: