
Home
Unlabelled
Advanced Hive Concepts and Data File Partitioning in Big data
Advanced Hive Concepts and Data File Partitioning in Big data
In this lesson, we will discuss Advanced Hive Concepts and Data File Partitioning Tutorial
Welcome to the lesson ‘Advanced Hive Concept and Data File Partitioning’ which is a part of ‘big data and hadoop training’ offered by OnlineItGuru.
This lesson covers an overview of the partitioning features of HIVE, which are used to improve the performance of SQL queries. You will also learn about the Hive Query Language and how it can be extended to improve query performance.
Let us look at the objectives first.
Objectives
After completing this lesson, you will be able to:
- Improve query performance with the concepts of data file partitioning in hive
- Define HIVE Query Language or HIVEQL
- Describe ways in which HIVEQL can be extended
You can check the Course Preview of big data and hadoop course
Let us look at the data storage in a single Hadoop Distributed File System.
Data Storage in a single Hadoop Distributed File System
HIVE is considered a tool of choice for performing queries on large datasets, especially those that require full table scans. HIVE has advanced partitioning features.
Data file partitioning in hive is very useful to prune data during the query, in order to reduce query times. There are many instances where users need to filter the data on specific column values.
- Using the partitioning feature of HIVE that subdivides the data, HIVE users can identify the columns, which can be used to organize the data.
- Using partitioning, the analysis can be done only on the relevant subset of data, resulting in a highly improved performance of HIVE queries.
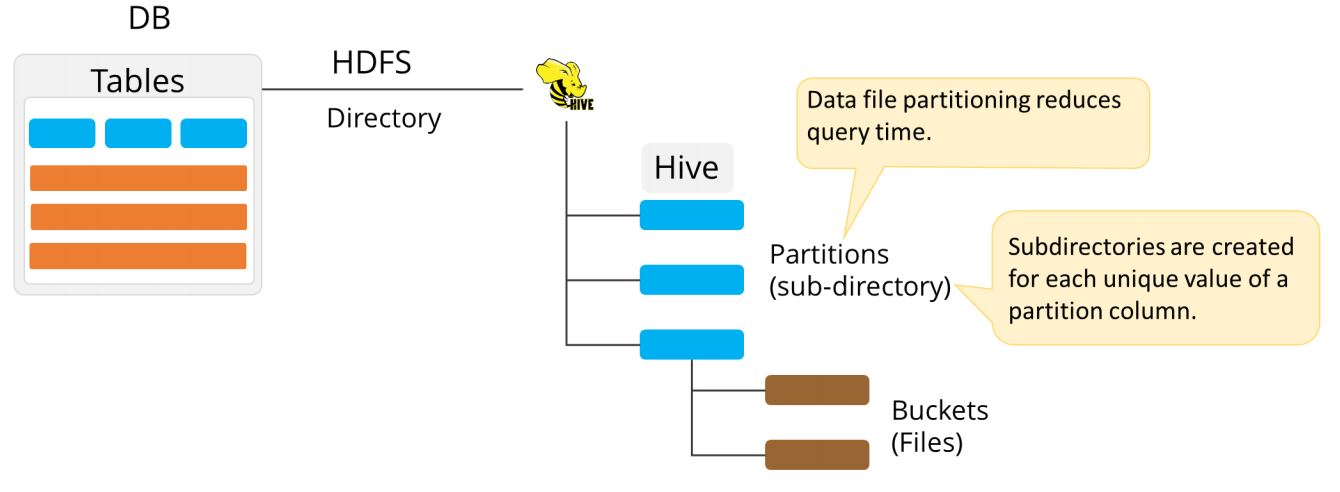
In case of partitioned tables, subdirectories are created under the table’s data directory for each unique value of a partition column. You will learn more about the partitioning features in the subsequent sections.
The following diagram explains data storage in a single Hadoop Distributed File System or HDFS directory.
 Let’s begin with an example of a non-partitioned table.
Let’s begin with an example of a non-partitioned table.Example of a Non-Partitioned Table
In non-partitioned tables, by default, all queries have to scan all files in the directory. This means that HIVE will need to read all the files in a table’s data directory. This can be a very slow and expensive process, especially when the tables are large.
In the example given below, you can see that there is a State column created in HIVE.
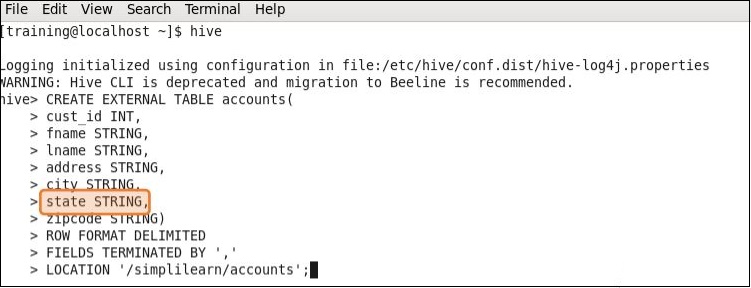
The requirement is to convert this to a state-wise partition so that separate tables are created for separate states. The customer details are required to be partitioned by the state for fast retrieval of subset data pertaining to the customer category.
Remember that you can perform the same queries in Impala as well.
In the next section, you will see an example of how this table is partitioned state-wise so that a full scan of the entire table is not required.
Example of a Partitioned Table
Here is an example of a partitioned table. This example shows you how the previously non-partitioned table is now partitioned.
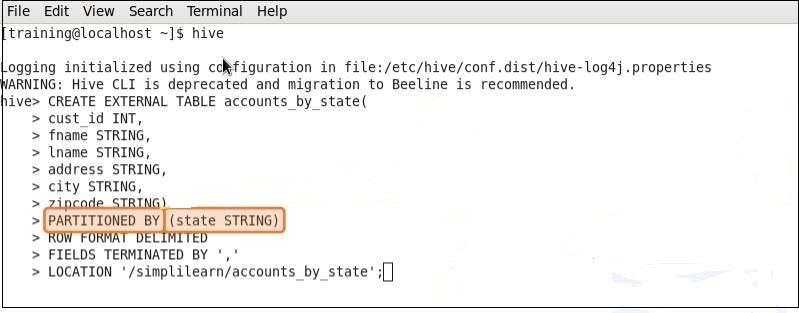
You can see that the state column is no longer included in the Create table definition, but it is included in the partition definition.
Partitions are actually horizontal slices of data that allow larger sets of data to be separated into more manageable chunks. This essentially means that you can use partitioning in hive to store data in separate files by state, as shown in the example.
At the time of table creation, partitions are defined using the PARTITIONED BY clause, with a list of column definitions for partitioning. A partition column is a “virtual column, where data is not actually stored in the file.
In the next section, let’s understand how you can insert data into partitioned tables using Dynamic and Static Partitioning in hive.
Dynamic and Static Partitioning in hive
Data insertion into partitioned tables can be done in two ways or modes: Static partitioning Dynamic partitioning
You will learn more about these concepts in the subsequent sections. Let’s begin with static partitioning.
Static Partitioning in Hive
In the static partitioning mode, you can insert or input the data files individually into a partition table. You can create new partitions as needed, and define the new partitions using the ADD PARTITION clause.
While loading data, you need to specify which partition to store the data in. This means that with each load, you need to specify the partition column value. You can add a partition in the table and move the data file into the partition of the table.
As you can see in the below example, you can add a partition for each new day of account data.
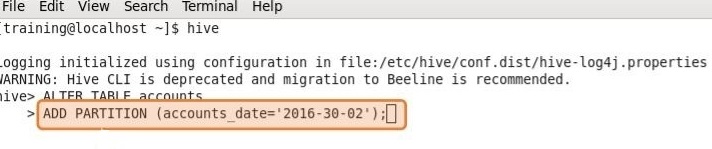
Let us now look at the Dynamic Partitioning in Hive.
Dynamic Partitioning in Hive
With dynamic partitioning in hive, partitions get created automatically at load times. New partitions can be created dynamically from existing data.
Partitions are automatically created based on the value of the last column. If the partition does not already exist, it will be created.
In case the partition does exist, it will be overwritten by the OVERWRITE keyword as shown in the below example.

As you see in the example, a partition is being overwritten. When you have a large amount of data stored in a table, then the dynamic partition is suitable.
Note that by default, dynamic partitioning is disabled in HIVE to prevent accidental partition creation.
Enable the following settings to use dynamic partitioning:
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;.
Let’s take a look at some commands that are supported on Hive partitioned tables, which allow you to view and delete partitions.
Viewing and Deleting Partitions
You can view the partitions of a partitioned table using the SHOW command, as illustrated in the image.

To delete drop the partitions, use the ALTER command, as shown in the image.
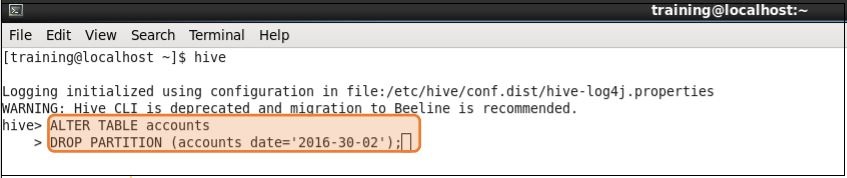
By using the ALTER command, you can also add or change partitions.
When to use partitioning?
Here are some instances when you use partitioning for tables:
- Reading the entire data set takes too long.
- Queries almost always filter on the partition columns.
- There are a reasonable number of different values for partition columns.
Here are some instances when you should avoid using a partitioning:
- Avoid partition on columns that have too many unique rows.
- Be cautious while creating a dynamic partition as it can lead to a high number of partitions.
- Try to limit partition to less than 20k.
Let us now understand what bucketing in HIVE is.
Bucketing in Hive
You’ve seen that partitioning gives results by segregating HIVE table data into multiple files only when there is a limited number of partitions. However, there may be instances where partitioning the tables results in a large number of partitions.
This is where the concept of bucketing comes in. Bucketing is an optimization technique similar to partitioning. You can use bucketing if you need to run queries on columns that have huge data, which makes it difficult to create partitions. The Bucketing optimization technique in Hive can be shown in the following diagram.
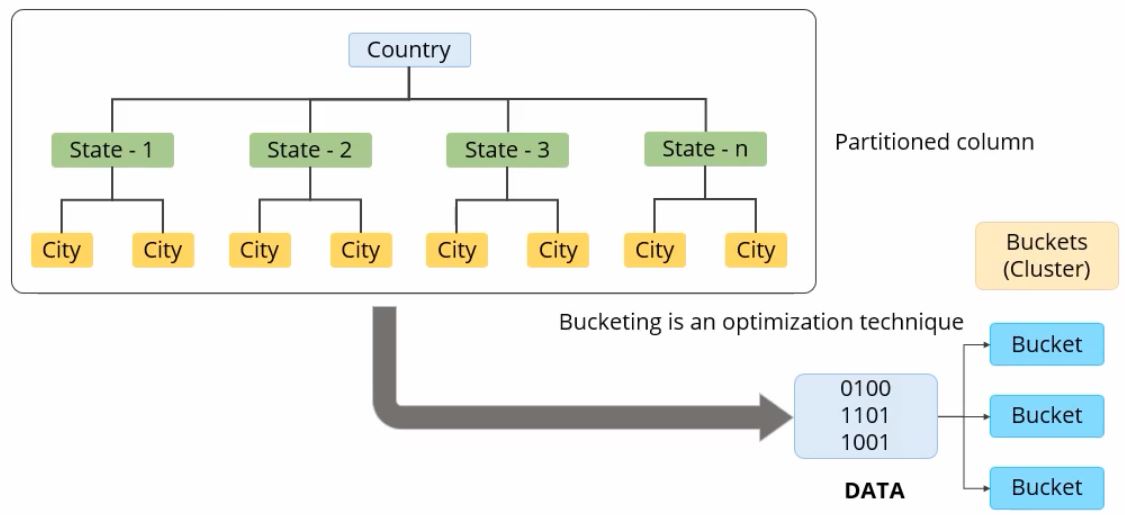
What Do Buckets Do?
They distribute the data load into a user-defined set of clusters by calculating the hash code of the key mentioned in the query.
Here is a syntax for creating a bucketing table.
CREATE TABLE page_views( user_id INT, session_id BIGINT, url
STRING)
PARTITIONED BY (day INT)
CLUSTERED BY (user_id) INTO 100;
As per the syntax, the data would be classified depending on the hash number of user underscore id into 100 buckets.
The processor will first calculate the hash number of the user underscore id in the query and will look for only that bucket.
Overview of Hive Query Language This is the second topic of the lesson.
In the next section of this lesson, let’s look at the concept of HIVE Query Language or HIVEQL, the important principle of HIVE called extensibility, and the ways in which HIVEQL can be extended.
Hive Query Language - Introduction
It’s the SQL-like query language for HIVE to process and analyze structured data in a Metastore. Below is an example of HIVEQL query.
SELECT
dt,
COUNT (DISTINCT (user_id))
FROM events
GROUP BY dt;
An important principle of HIVEQL is extensibility.
HIVEQL can be extended in multiple ways:
- Pluggable user-defined functions
- Pluggable MapReduce scripts
- Pluggable user-defined types
- Pluggable data formats
User-defined function(UDF)
HIVE has the ability to define a function.
- UDFs provide a way of extending the functionality of HIVE with a function, written in Java that can be evaluated in HIVEQL statements. All UFDs extend the HIVE UDF class.
- A UDF subclass needs to implement one or more methods named evaluate, which will be called by HIVE. Evaluate should never be a void method. However, it can return null, if required.
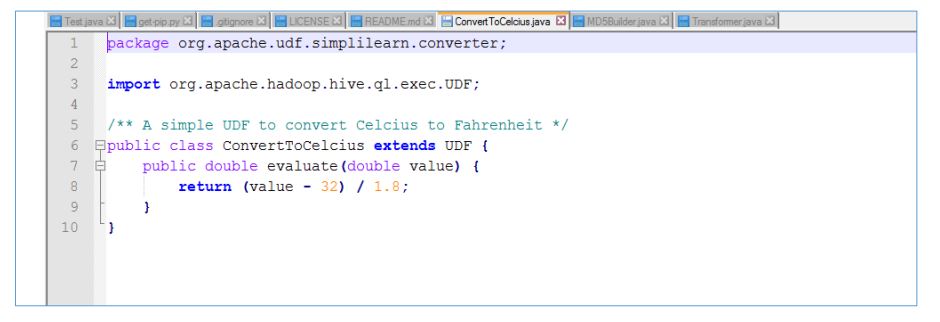
Hive UDF Example 1
To convert any value to Celsius:
Hive UDF Example 2
To converts any string to hash code:
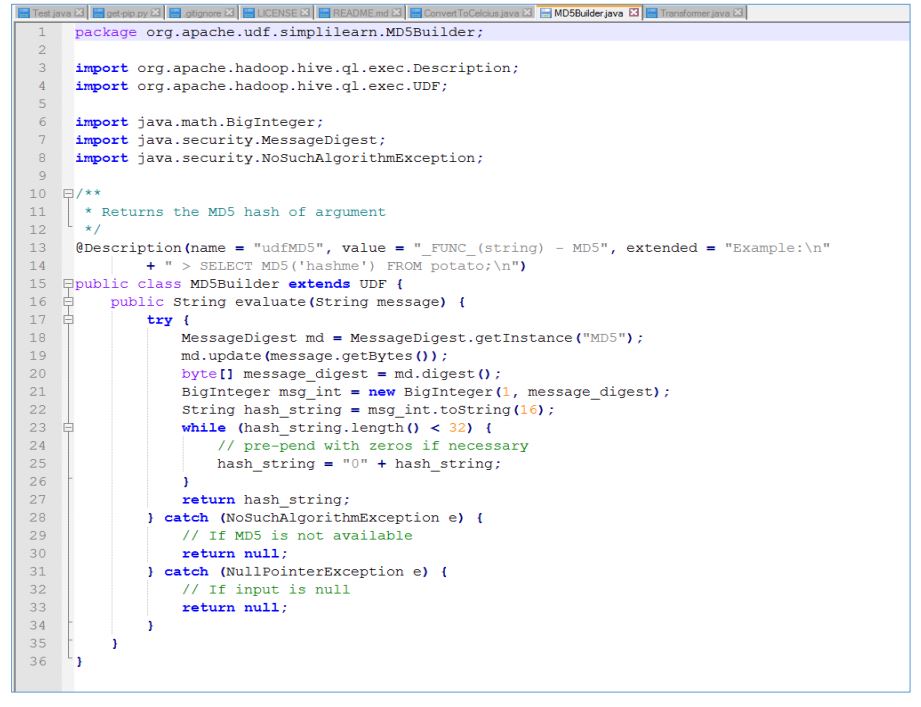
Here, A hash code is a number generated from any object. It allows objects to be stored/retrieved quickly in a hash table.
Hive UDF Example 3
To transform already created database by the overriding method when you need to insert a new column:
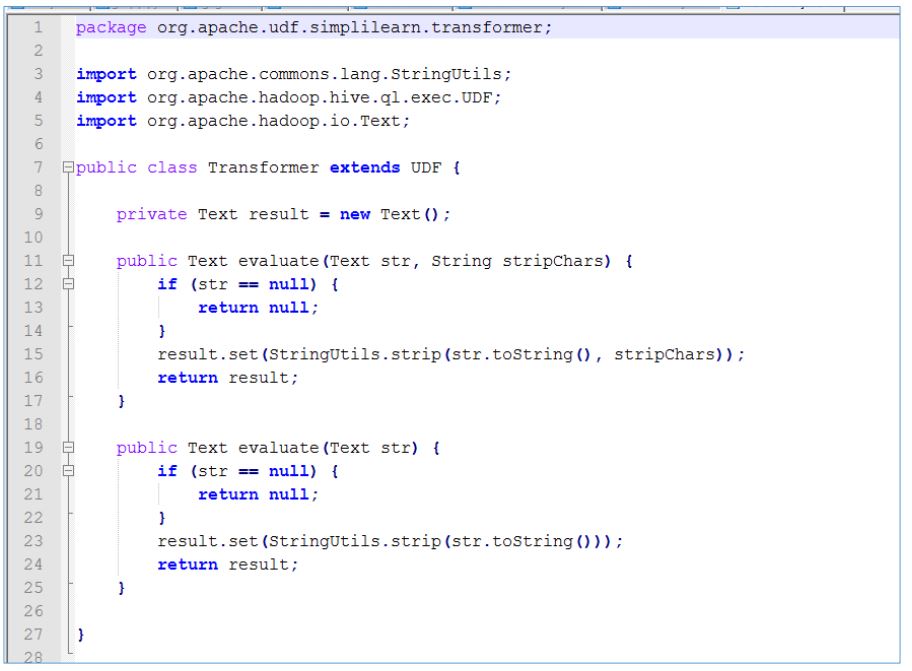
Now let us understand a code to extend the user-defined function.
Code for Extending UDF
Here is a code that you can use to extend the user-defined function.
package com.example.hive.udf;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
public final class Lower extends UDF {
public Text evaluate(final Text s) {
if (s == null) { return null; }
return new Text(s.toString().toLowerCase());
}
}
User-Defined Function-codes
After compiling the UDF, you must include it in the HIVE classpath. Here is a code that you can use to register the class.
CREATE FUNCTION my_lower AS ‘com.example.hive.udf.Lower’;
Once HIVE gets started, you can use the newly defined function in a query statement after registering them. This is a code to use the function in a HIVE query statement.
SELECT my_lower(title), sum(freq) FROM titles GROUP BY my_lower(title);
Writing the functions in JavaScript creates its own UDF. HIVE also provides some inbuilt functions that can be used to avoid own UDFs from being created.
Let’s take a look at what these inbuilt functions are.
Built-in functions of Hive
Writing the functions in JAVA scripts creates its own UDF. Hive also provides some inbuilt
functions that can be used to avoid own UDFs from being created.
These include Mathematical, Collection, Type conversion, Date, Conditional, and String. Let’s look at the examples provided for each built-in functions.
- Mathematical: For mathematical operations, you can use the examples of the round, floor, and so on.
- Collection: For collections, you can use size, map keys, and so on.
- Type conversion: For data type conversions, you can use a cast.
- Date:For dates, use the following APIs like a year, datediff, and so on.
- Conditional: For conditional functions, use if, case, and coalesce.
- String: For string files, use length, reverse, and so on.
Let’s look at some other functions in HIVE, such as the aggregate function and the table-generating function.
Aggregate functions
Aggregate functions create the output if the full set of data is given. The implementation of these functions is complex compared with that of the UDF. The user should implement a few more methods, however, the format is similar to UDF.
Therefore, HIVE provides many built-in User-Defined Aggregate Functions or UDAF.
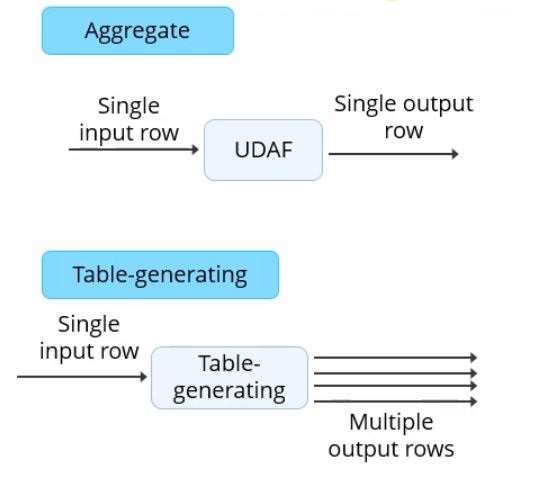
Table-generating functions
Normal user-defined functions, namely concat, take in a single input row and give out a single output row. In contrast, table-generating functions transform a single input row to multiple output rows.
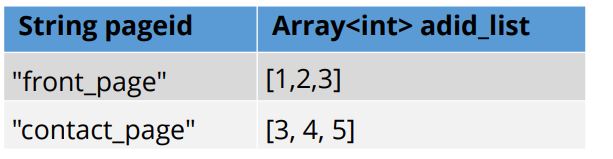
Consider the base table named pageAds. It contains two columns: pageid, which is the name of the page and adid underscore list, which is an array of ads appearing on the page.
Shown here is a lateral view that is used in conjunction with table generating functions.
An SQL script in lateral view is:
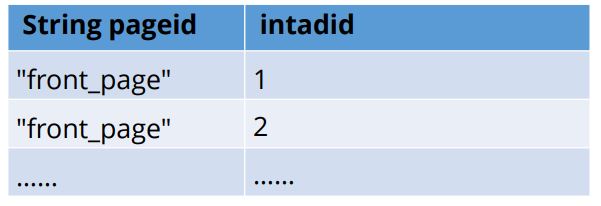
SELECT pageid, adid FROM pageAds
LATERAL VIEW explode(adid_list) adTable
AS adid;
A lateral view with exploding can be used to convert the adid underscore list into separate rows using the given query.
Let’s take a look at the MapReduce Scripts that helps extend the HIVEQL.
MapReduce Scripts
MapReduce scripts are written in scripting languages such as Python. Users can plug in their own custom mappers and reducers in the data stream.
To run a custom mapper script and reducer script, the user can issue a command that uses the TRANSFORM clause to embed the mapper and the reducer scripts.
Look at the script shown in below.
Example: my_append.py
SELECT TRANSFORM (foo, bar) USING 'python ./my_append.py' FROM sample;
For line in sys.stdin:
line = line.strip()
key = line.split('t')[0]
value = line.split('t')[1]
print key+str(i)+'t'+value+str(i)
i=i+1
Here the key-value pairs will be transformed to STRING and delimited by TAB before feeding to the user script by default.
The method strip returns a copy of all of the words in which whitespace characters have been stripped from the beginning and the end of the word. The method split returns a list of all of the words using TAB as the separator.
Let’s compare the user-defined and user-defined aggregate functions with MapReduce scripts.
UDF/UADF versus MapReduce Scripts
A comparison of the user-defined and user-defined aggregate functions with MapReduce scripts are shown in the table given below.
Attribute
|
UDF/UDAF
|
MapReduce scripts
|
Language
|
Java
|
Any language
|
1/1 input/output
|
Supported via UDF
|
Supported
|
n/1 input/output
|
Supported via UDAF
|
Supported
|
1/n input/output
|
Supported via UDTF
|
Supported
|
Speed
|
Faster (in the same process)
|
Slower (spawns new process)
|
You should also consider taking a big data hadoop certification course here.
Summary
Now let’s summarize what we learned in this lesson.
- Partitions are actually horizontal slices of data that allow larger sets of data to be separated into more manageable chunks.
- In the static partitioning mode, you can insert or input the data files individually into a partition table.
- When you have a large amount of data stored in a table, then the dynamic partition is suitable.
- Use the SHOW command to view partitions.
- To delete or add partitions, use the ALTER command.
- Use partitioning when reading the entire data set takes too long, queries almost always filter on the partition columns, and there are a reasonable number of different values for partition columns.
- HIVEQL is a query language for HIVE to process and analyze structured data in a Metastore.
- HIVEQL can be extended with the help of user-defined functions, MapReduce scripts, user-defined types, and data formats.
Conclusion
This concludes the lesson on ‘Advanced Hive Concept and Data File Partitioning’.
Advanced Hive Concepts and Data File Partitioning in Big data
![Advanced Hive Concepts and Data File Partitioning in Big data]() Reviewed by veera
on
July 14, 2020
Rating: 5
Reviewed by veera
on
July 14, 2020
Rating: 5



No comments: